Im Internet gibt es sehr viel identisches Material. Laut einer Aussage von Matt Cutts sind schätzungsweise 25 bis 30 Prozent aller Webinhalte doppelt vorhanden.
Für Ihre Website kann das ernste Folgen haben. Suchmaschinen bestrafen doppelte Inhalte oft mit einem schlechteren Ranking.
Ihre Seiten verlieren an Sichtbarkeit. Gleichzeitig leidet der Mehrwert für den Besucher.
Dieser professionelle Guide hilft Ihnen, das Problem zu verstehen. Sie lernen, wie Sie doppelte Einträge identifizieren und gezielt beheben.
Wir zeigen Ihnen praktische Tools wie die Google Search Console. Technische Lösungen wie Canonical-Tags und klare URLs stehen im Fokus.
Unser Ziel ist Ihre nachhaltig verbesserte SEO-Performance. Ein effizientes Crawling-Budget für Ihren Crawler und starke Rankings sind das Ergebnis.
Schlüsselerkenntnisse
- Doppelte Inhalte sind ein weit verbreitetes Problem im Web.
- Sie können das Ranking Ihrer Webseiten bei Google negativ beeinflussen.
- Eine klare und konsistente URL-Strategie ist für jedes Unternehmen essenziell.
- Mit Tools wie der Google Search Console können Sie Duplikate systematisch aufspüren.
- Technische Hilfsmittel wie Canonical-Tags leiten Suchmaschinen zur bevorzugten Version.
- Die Unterscheidung zwischen internen und externen Duplikaten ist für die richtige Lösung wichtig.
- Durch die Behebung des Problems nutzen Sie das Crawling-Budget Ihrer Seite effizienter.
Was ist Duplicate Content und warum ist es problematisch?
Viele Webseitenbetreiber stehen vor der Herausforderung, dass identische Texte unter mehreren Adressen erreichbar sind. Dieses Phänomen erschwert es Suchmaschinen, die relevante Version einer Seite zu bestimmen.
Das kann für Ihre Präsenz ein ernstes Problem darstellen. Es beeinträchtigt die klare Kommunikation mit Crawlern und verbraucht wertvolle Ressourcen.
Definition und grundlegende Ursachen
Unter Duplicate Content versteht man weitgehend gleiche Inhalte, die auf unterschiedlichen URLs einer Website zugänglich sind. Eine häufige technische Ursache ist das Fehlen eines klaren kanonischen Verweises.
Dies führt dazu, dass Crawler denselben Inhalt mehrfach erfassen. Die Struktur Ihrer Webadressen spielt hier eine zentrale Rolle.
Die Rolle von identischen Inhalten in der SEO
Für Suchmaschinen wie Google sind einzigartige Texte ein wichtiges Qualitätsmerkmal. Stoßen sie auf identische Inhalte, kann die Autorität Ihrer Seite in den Suchergebnissen leiden.
Nutzer erwarten bei ihrer Suche einen klaren Mehrwert. Doppelte Einträge bieten diesen nicht und verschlechtern das Nutzererlebnis.
Technische Ursachen von doppelten Inhalten
Viele Probleme mit gleichen Texten entstehen durch unbeabsichtigte URL-Varianten. Ihre Website kann technisch bedingt mehrere Adressen für denselben Inhalt bereitstellen.
Suchmaschinen bewerten diese Versionen dann als separate Seiten. Das führt zu einer ineffizienten Nutzung Ihres Crawling-Budgets.
URL-Varianten und Session-IDs
Session-IDs in der URL sind ein klassisches Problem. Jede Nutzersitzung generiert eine neue Adresse für die gleiche Seite.
Suchmaschinen crawlen diese als unterschiedliche URLs. Ein weiteres Beispiel ist die Erreichbarkeit Ihrer Domain mit und ohne www-Präfix.
Für Crawler wirkt das wie zwei separate Domains. Beide zeigen aber identische Inhalte.
Paginierung und Parameter
Paginierte Listen oder Filter-Optionen erzeugen oft Parameter in der URL. Eine Kategorie-Seite mit Sortierfunktionen kann viele neue Pfade schaffen.
Der eigentliche Inhalt bleibt gleich. Suchmaschinen indexieren jedoch jede Variante einzeln.
Das verursacht doppelte Einträge und kann zu einem Rankingverlust führen.
| Technische Ursache | Beschreibung | Typische Lösung |
|---|---|---|
| Session-IDs in URLs | Jede Sitzung erzeugt eine neue URL für denselben Inhalt. | Session-Informationen server-seitig speichern. |
| www vs. non-www | Zwei Domain-Versionen zeigen identische Inhalte. | Kanonische Domain in den Server-Einstellungen festlegen. |
| Paginierung | Seitenzahlen generieren viele URLs für gleiche Inhalte. | rel=“next“/“prev“ Tags oder Canonical-Tags nutzen. |
| URL-Parameter (Sortierung, Filter) | Parameter ändern die URL, nicht den Kerninhalt. | Parameter in der Search Console für das Crawling kennzeichnen. |
Inhaltliche Ursachen für Duplicate Content
Neben technischen Fehlern führen auch inhaltliche Entscheidungen oft zu doppelten Einträgen auf Ihrer Website. Diese Ursachen liegen in der Art und Weise, wie Sie Texte erstellen und verwenden.
Wiederverwendung von Textbausteinen
Die ständige Nutzung identischer Textblöcke, bekannt als Boilerplate-Content, ist ein großes Problem. Ein typisches Beispiel sind rechtliche Hinweise im Footer.
Solche Abschnitte erscheinen auf jeder Seite Ihrer Domain. Für Crawler wirken sie wie kopierte Inhalte.
Ein weiteres Risiko ist die Veröffentlichung eines Artikels auf mehreren Seiten. Geschieht dies ohne neuen Mehrwert, sehen Suchmaschinen nur gleiches Material.
Besonders kritisch ist die Praxis in Online-Shops. Viele Betreiber übernehmen Herstellerbeschreibungen unverändert.
Ihre Website zeigt dann exakt dieselben Texte wie tausend andere. Die Lösung liegt in individuellen Anpassungen.
Schreiben Sie für jeden Artikel einen einzigartigen Text. So vermeiden Sie, dass Ihre Seiten als minderwertig eingestuft werden.
Planen Sie Ihre Inhalte strategisch. Jede URL sollte einen eigenständigen Nutzen bieten.
Auswirkungen von Duplicate Content auf das Ranking
Die Bewertung doppelter Inhalte durch Suchmaschinen entscheidet maßgeblich über Ihre Sichtbarkeit. Ihr Ranking kann leiden, wenn Crawler mehrere Versionen desselben Textes vorfinden.
Sie müssen dann entscheiden, welche Seite die beste ist. Diese Aufteilung der Relevanz schwächt oft alle beteiligten URLs.
Wie Suchmaschinen doppelten Content bewerten
Matt Cutts, ein früherer Google-Experte, erklärte einen wichtigen Punkt. Identisches Material ist nicht grundsätzlich schädlich, es sei denn, es dient der Manipulation.
Suchmaschinen bewerten die Qualität Ihrer Inhalte. Sie suchen nach der originären Quelle, um diese zu priorisieren.
Ein technischer Fall kann dazu führen, dass eine wichtige Seite nicht indexiert wird. Ihre Website verliert so an Sichtbarkeit in den Ergebnissen.
Durch korrekte technische Behandlung schützen Sie Ihr Projekt vor Verlusten. Sie stellen sicher, dass Ihre bevorzugte Seite das beste Ranking erhält.
| Szenario | Bewertung durch Suchmaschine | Mögliche Auswirkung auf Ranking |
|---|---|---|
| Technische URL-Varianten (z.B. mit Parameter) | Crawler sehen separate Seiten mit gleichem Inhalt. | Relevanz wird aufgeteilt; wichtige Seite rankt schlechter. |
| Inhaltliche Wiederholung (z.B. Footer-Text) | Wird als minderwertiger, nicht einzigartiger Inhalt eingestuft. | Gesamte Domain kann an Autorität verlieren. |
| Extern kopierte Beschreibungen | Suchmaschinen identifizieren die originale Quelle. | Ihre Seite erhält möglicherweise kein Ranking für diesen Inhalt. |
Google und der Umgang mit Duplicate Content
Als führende Suchmaschine hat Google spezielle Algorithmen zur Erkennung von Duplikaten entwickelt. Diese Systeme bewerten, wie Ihre Website mit gleichem Material umgeht.
Ihr Ranking hängt direkt von diesem Prozess ab. Google priorisiert stets die originäre Quelle.
Google-Algorithmen und Indexierung
Die Algorithmen analysieren Milliarden von URLs. Sie identifizieren schnell doppelte Inhalte.
Laut Schätzungen sind 25 bis 30 Prozent des Webs betroffen. Googles Crawler verschwenden keine Zeit auf Kopien.
Das beschleunigt die Indexierung Ihrer einzigartigen Texte. Ihre Seite gewinnt an Sichtbarkeit.
Eine korrekte technische Auszeichnung ist hier essenziell. Sie leitet die Suchmaschine zur bevorzugten Version.
Missbrauch kann eine manuelle Google Penalty auslösen. Ihr gesamtes Projekt droht dann ein Ranking-Verlust.
Verstehen Sie die Logik der Algorithmen. So optimieren Sie Ihre Performance in der Google Search.
Duplicate Content finden: Analyse und geeignete Tools
Die systematische Suche nach gleichen Texten ist der erste Schritt zu einer sauberen Website-Struktur. Ohne spezielle Werkzeuge bleiben viele Probleme mit doppelten Einträgen unentdeckt.
Moderne Analysemethoden kombinieren automatisches Scannen und manuelle Prüfung. So schützen Sie Ihr Ranking effektiv.
Einsatz von Siteliner und Copyscape
Für internen duplicate content ist Siteliner eine ausgezeichnete Wahl. Das Tool durchsucht Ihre gesamte Website nach identischen Textblöcken.
Es zeigt Ihnen exakt, welche Seiten betroffen sind. So können Sie die Qualität Ihrer Inhalte gezielt verbessern.
Die Erkennung von externen duplicate content übernimmt Copyscape. Es prüft, ob andere Domains Ihre Texte ohne Erlaubnis kopiert haben.
Diese Kontrolle ist für den Schutz Ihrer einzigartigen Artikel essenziell.
Die Google Search Console liefert zusätzliche wertvolle Daten. Im Bericht „Abgedeckte Seiten“ sehen Sie Indexierungsprobleme.
Ergänzend können Sie mit gezielten Suche-Operatoren in Suchmaschinen manuell nach Kopien suchen. Ein regelmäßiger Check aller URLs gehört zur guten SEO-Praxis.
Für eine vertiefte Betrachtung empfehlen wir unseren umfassenden Leitfaden zu doppelten Inhalten. Dort finden Sie detaillierte Anleitungen zur Interpretation der Tool-Ergebnisse.
Durch die Kombination dieser Methoden stellen Sie sicher, dass keine doppelten Inhalte Ihr Projekt gefährden.
Unterschied zwischen internem und externem Duplicate Content
Um doppelte Inhalte effektiv zu bekämpfen, müssen Sie zunächst deren Herkunft genau bestimmen. Die Lösung hängt maßgeblich davon ab, ob die identischen Texte innerhalb Ihrer eigenen Struktur oder auf fremden Servern liegen.
Diese Unterscheidung ist für Ihre SEO-Strategie fundamental. Sie entscheidet über die richtigen technischen und inhaltlichen Gegenmaßnahmen.
Beispiele und typische Szenarien
Interner duplicate content entsteht auf Ihrer eigenen Website. Ein klassisches Beispiel sind Produktseiten, die über mehrere Kategorie-URLs erreichbar sind.
Fehlt ein klares Canonical-Tag, indexieren Suchmaschinen jede Variante. Das schwächt die Relevanz Ihrer wichtigsten Seite.
Externer duplicate content liegt vor, wenn andere Domains Ihre Texte ohne Erlaubnis kopieren. Besonders betroffen sind Unternehmen mit internationalen Niederlassungen.
Oft werden Inhalte für verschiedene Länder auf separaten Domains veröffentlicht. Das führt zu identischen Versionen im Web.
Die Identifizierung der Quelle ist entscheidend. Für interne Probleme sind oft 301-Weiterleitungen die beste Lösung.
Bei externen Kopien müssen Sie die Urheberschaft klären und gegebenenfalls rechtliche Schritte einleiten. So schützen Sie die Sichtbarkeit Ihrer originalen Inhalte.
Best Practices zur Vermeidung von Duplicate Content
Der Schlüssel zur langfristigen Stärkung Ihrer Online-Präsenz liegt in proaktiven Maßnahmen gegen doppelte Einträge. Durch vorbeugende Strategien sparen Sie Zeit und schützen Ihr Ranking.
Die wichtigste Regel ist die Erstellung einzigartiger Inhalte. Jede Ihrer Seiten sollte einen klaren Mehrwert bieten.
Technisch setzen Sie auf eine saubere URL-Struktur. Vermeiden Sie unnötige Parameter und nutzen Sie konsequent Canonical-Tags.
Diese Tags teilen Suchmaschinen mit, welche Version Ihrer Website bevorzugt werden soll. So lenken Sie die Crawler effizient.
Regelmäßige Audits helfen, Probleme früh zu erkennen. Überprüfen Sie Ihre URLs und Seiten in festen Intervallen.
Konfigurieren Sie Ihre .htaccess-Datei korrekt. Stellen Sie sicher, dass nur eine Domain-Version indexiert wird.
Diese Praktiken bauen Vertrauen bei Suchmaschinen auf. Sie beugen auch duplicate content durch technische Konfigurationsfehler wirksam vor.
Schützen Sie Ihre originalen Inhalte vor Scraping. So verhindern Sie externen duplicate content und stärken Ihre Autorität.
Techniken zur Behebung von Duplicate Content
Effektive Methoden zur Beseitigung identischer Texte stärken Ihre Online-Sichtbarkeit nachhaltig. Sie verhindern, dass Suchmaschinen wertvolle Ressourcen verschwenden.
Ihr Ranking profitiert direkt von einer sauberen Struktur. Jede Maßnahme zielt darauf ab, klare Signale an Crawler zu senden.
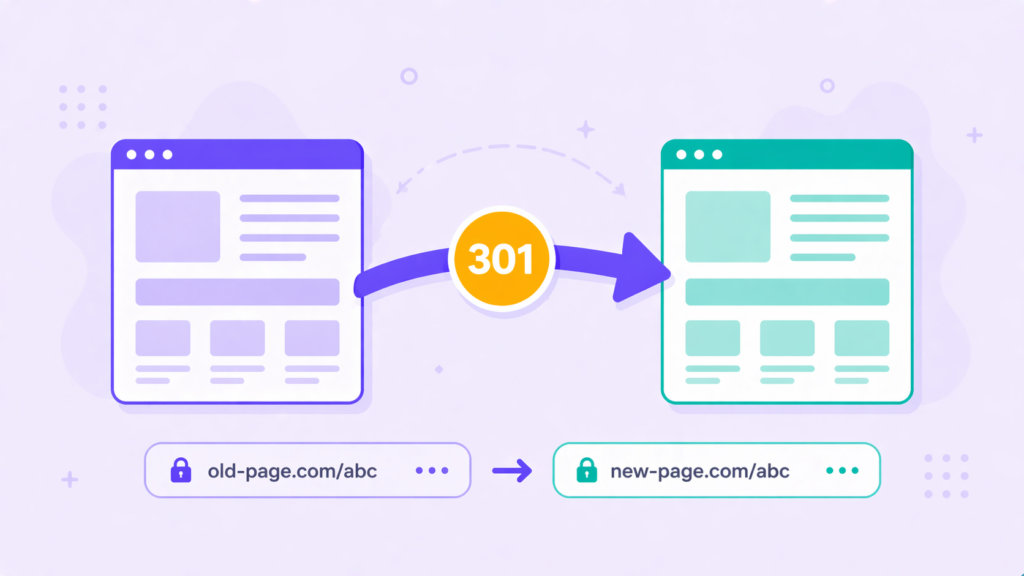
Anwendung von 301 Redirects
Ein 301 Redirect ist die dauerhafte Lösung für veraltete Adressen. Er leitet Nutzer und Suchmaschinen automatisch zur neuen URL.
Das Ranking der alten Seite wird vollständig übertragen. Dieser Fall ist ideal, wenn Sie einen Artikel konsolidieren oder eine Domain wechseln.
So beheben Sie duplicate content technisch einwandfrei. Ihre Website gewinnt an Autorität.
Optimierung der Inhalte und URL-Struktur
Überprüfen Sie alle Inhalte auf Einzigartigkeit. Jede Seite sollte einen klaren Mehrwert bieten.
Vermeiden Sie identische Textblöcke auf verschiedenen URLs. Eine konsistente Adressstruktur erleichtert die Indexierung.
Canonical-Tags ergänzen diese Optimierung. Sie zeigen Suchmaschinen die bevorzugte Version für das Ranking an.
Durch diese Schritte lösen Sie das Problem doppelter Einträge. Ihre Inhalte erreichen ihre maximale Wirkung.
Umgang mit URL-Parametern und Session-IDs
Filter- und Sortierfunktionen, aber auch Tracking-Systeme, können ungewollt zahlreiche Adressvarianten für ein und dieselbe Seite produzieren. Diese Parameter in der URL führen oft zu technischem duplicate content.
Filterung und technische Lösungsansätze
Ein klassisches Beispiel sind Tracking-Parameter oder Session-IDs. Jeder Klick erzeugt eine neue Adresse, obwohl der Inhalt identisch bleibt.
Suchmaschinen crawlen diese Varianten als separate Seiten. Das verschwendet Ihr Budget und kann Probleme verursachen.
Die primäre Lösung ist die Verwendung des Canonical-Tags. Dieses Tag zeigt Crawlern die kanonische, also die Hauptversion Ihrer Seite an.
So indexieren Suchmaschinen trotz Parametern korrekt. Eine ergänzende Maßnahme ist die Konfiguration in der Search Console.
Hier teilen Sie Google mit, welche Parameter ignoriert werden sollen. Dies folgt den offiziellen Google-Richtlinien.
Durch diese Filterung verhindern Sie, dass unnötige Duplikate Ihrer Inhalte gecrawlt werden. Ihre Website bleibt sauber und effizient.
| Parameter-Typ | Beschreibung | Technische Lösung |
|---|---|---|
| Tracking-Parameter (z.B. utm_source) | Werden für Kampagnen-Tracking angehängt, ändern aber nicht den Seiteninhalt. | Canonical-Tag auf die Parameter-freie URL setzen. |
| Session-IDs | Identifizieren Nutzersitzungen und erstellen für jeden Besuch eine unique URL. | Session-Informationen in Cookies speichern, nicht in der URL. |
| Filter- & Sortierparameter | Erlauben Nutzern, Listen zu filtern, generieren viele URL-Varianten. | In der Google Search Console als „Ignoriert“ markieren; Canonical auf Haupt-URL. |
Nutzen von Canonical Tags und serverseitigen Weiterleitungen
Canonical Tags und serverseitige Weiterleitungen sind zwei der effektivsten Werkzeuge, um Suchmaschinen klare Signale zu geben. Sie lösen das Problem doppelter Einträge direkt an der Wurzel. Ihre Website gewinnt so eine eindeutige Struktur.
Der primäre Nutzen liegt in der gezielten Lenkung von Crawlern. Sie teilen explizit mit, welche Version einer Seite als Original für das Ranking gelten soll. So verhindern Sie, dass Ihre Inhalte als duplicate content eingestuft werden.
Implementierung und Beispiele
Setzen Sie den Canonical-Tag korrekt im Head-Bereich Ihrer HTML-Seiten. Ein Beispiel: Für die URL `ihredomain.de/produkt?sessionid=abc` verweist das Tag auf `ihredomain.de/produkt. Suchmaschinen indexieren nur die kanonische URL.
Serverseitige Weiterleitungen, wie ein 301 Redirect, entfernen duplicate content dauerhaft. Legen Sie in Ihrer .htaccess-Datei fest, dass alle Aufrufe der Domain ohne „www“ auf die Version mit „www“ umgeleitet werden. Die Linkautorität wird vollständig übertragen.
Die Kombination beider Techniken schafft maximale Klarheit. Ihre Website wird als vertrauenswürdige Quelle für einzigartige inhalte wahrgenommen. Dies stärkt Ihre SEO-Performance nachhaltig und behebt duplicate content effizient.
Der Einsatz von noindex und hreflang zur Duplicate Content Vermeidung
Technische Tags wie noindex und hreflang bieten präzise Kontrolle über die Indexierung Ihrer Seiten. Sie lösen spezifische Probleme mit identischen Texten.
Der noindex-Befehl schließt bestimmte URLs vollständig aus dem Suchindex aus. Das ist ideal für Seiten mit geringem Mehrwert oder doppelten Inhalten.
Für Unternehmen mit internationaler Präsenz ist das hreflang-Attribut unverzichtbar. Es verknüpft lokalisierte Versionen Ihrer Website korrekt.
Ein häufiges Problem ist, dass Suchmaschinen gleiche Inhalte in verschiedenen Sprachen als Duplikate einstufen. Das schadet Ihrem Ranking.
Hreflang-Tags zeigen den Crawlern explizit die richtige Version für jede Region an. So wird die passende Seite in der Google Search ausgespielt.
Durch die Kombination beider Methoden vermeiden Sie duplicate content effektiv. Ihre Sichtbarkeit verbessert sich nachhaltig.
Überwachen Sie die Implementierung in der Google Search Console. Stellen Sie sicher, dass keine falschen Versionen indexiert werden.
Ein praktisches Beispiel ist die Verknüpfung deutscher und österreichischer Seitenvarianten. So verhindern Sie duplicate content im gleichen Sprachraum.
Die korrekte Anwendung stellt sicher, dass Ihre Website global optimal performt. Sie beheben damit einen kritischen Fall für Ihre internationale Suche.
Abschluss: Ihre nächsten Schritte zur Optimierung Ihrer Inhalte
Mit dem Wissen aus diesem Guide sind Sie nun bestens gerüstet, Ihre Online-Inhalte auf ein neues Level zu heben. Ihr nächstes Ziel sollte die regelmäßige Überprüfung Ihrer Website sein, um doppelte Einträge früh zu erkennen.
Setzen Sie die beschriebenen Techniken auf jeder Seite schrittweise um. So steigern Sie kontinuierlich die Qualität Ihrer Inhalte.
Der beste Schutz ist die Erstellung einzigartiger Artikel mit echtem Mehrwert. Nutzen Sie die vorgestellten Tools für eine gründliche Analyse.
Bleiben Sie wachsam gegenüber Kopien Ihrer Texte auf anderen Domains. Ergreifen Sie bei Bedarf Maßnahmen zum Schutz Ihrer Website.
Durch konsequente Optimierung stellen Sie sicher, dass Suchmaschinen Ihre Inhalte als wertvoll einstufen. Dies festigt Ihr Ranking nachhaltig.
Wir hoffen, dieser Guide hilft Ihnen, Ihre Präsenz effektiv zu stärken und für die Zukunft optimal aufzustellen.
FAQ
Was genau versteht man unter identischen Inhalten und wieso sind sie schädlich?
Identische Inhalte liegen vor, wenn derselbe Text unter verschiedenen Adressen im Netz erreichbar ist. Für Suchmaschinen wie Google ist das problematisch, da sie nicht entscheiden können, welche Version im Ranking bevorzugt werden soll. Dies kann die Sichtbarkeit Ihrer Hauptseite schwächen.
Wie kann ich doppelte Texte auf meiner eigenen Webpräsenz aufspüren?
Nutzen Sie spezielle Tools für eine gründliche Prüfung. Siteliner analysiert Ihre gesamte Domain auf interne Kopien. Für einen Blick über Ihre Grenzen hinaus eignet sich Copyscape, um zu sehen, ob andere Ihre Artikel übernommen haben.
Welche technischen Fehler führen häufig zu diesem Problem?
Häufige Ursachen sind verschiedene URL-Varianten (z.B. mit und ohne „www“), Session-IDs oder Sortierparameter in Online-Shops. Auch eine schlechte Paginierung kann viele ähnliche Seiten ohne echten Mehrwert erzeugen, die Crawler verwirren.
Welche direkten Auswirkungen hat das auf meine Platzierung in den Suchergebnissen?
Suchmaschinen filtern doppelte Einträge oft aus, um dem Nutzer die beste Erfahrung zu bieten. Ihre Website riskiert, dass die falsche Version indexiert wird oder die Linkkraft zwischen den Duplikaten aufgeteilt wird. Beides schadet Ihrem Ranking.
Was ist der beste Weg, um mit URL-Parametern umzugehen?
Sie sollten Parameter, die keine inhaltliche Änderung bewirken (wie Tracking-Parameter), in der Google Search Console ignorieren lassen. Für wichtige Parameter (wie Filter) setzen Sie korrekte Canonical Tags, um die kanonische, also bevorzugte, URL festzulegen.
Wann sollte ich einen 301 Redirect verwenden?
Setzen Sie eine 301-Weiterleitung immer dann ein, wenn Sie alte oder überflüssige Seiten dauerhaft auf eine neue, relevante Adresse umleiten möchten. Dies konsolidiert die Linkstärke und teilt den Crawlern klar mit, welche Version für die Indexierung gültig ist.
Wie helfen hreflang-Attribute und der noindex-Befehl?
Das hreflang-Attribut kennzeichnet sprachliche oder regionale Versionen einer Seite für Suchmaschinen und beugt so Problemen vor. Der noindex-Befehl im Meta-Tag sagt Crawlern, bestimmte Seiten (wie interne Suchergebnisse) gar nicht erst in den Index aufzunehmen.